5 Er den tekniske riggen på plass?
5.1 Innledning
I dette kapittelet adresserer vi noen av de vurderingene som må gjøres for sikre en sikker og fleksibel teknisk plattform som støtter integrasjon, modellbytte og databeskyttelse. Merk at dette ikke er ment som en komplett beskrivelse av hvordan selskapets systemarkitektur kan se ut, men mer hvilke elementer man må ha på plass i forbindelse med innføring av en KI-assistent.
Litt avhengig av hvilke behov dere har, kan det være hensiktsmessig å etablere en plattform der dere har god nok kontroll over dataflyt, fleksibilitet i valg av språkmodell og som kan kobles til eksisterende systemer. I tillegg er det helt sentralt å ta hensyn til sikkerheten i systemet, og hvordan bruken loggføres. Det siste er viktig for kvalitetskontroll og kontinuerlig forbedring av KI-systemet.
Også ved innføring av en åpen KI-assistent er det vurderinger som bør gjøres ved valg av modell og arkitektur, men disse vurderingene er enklere enn om dere tilpasser en løsning.
For forståelse av de ulike nivåene av KI-assistenter tas det utgangspunkt i oversikten fra kapittel 2.5.
5.2 Valg av modell og arkitektur
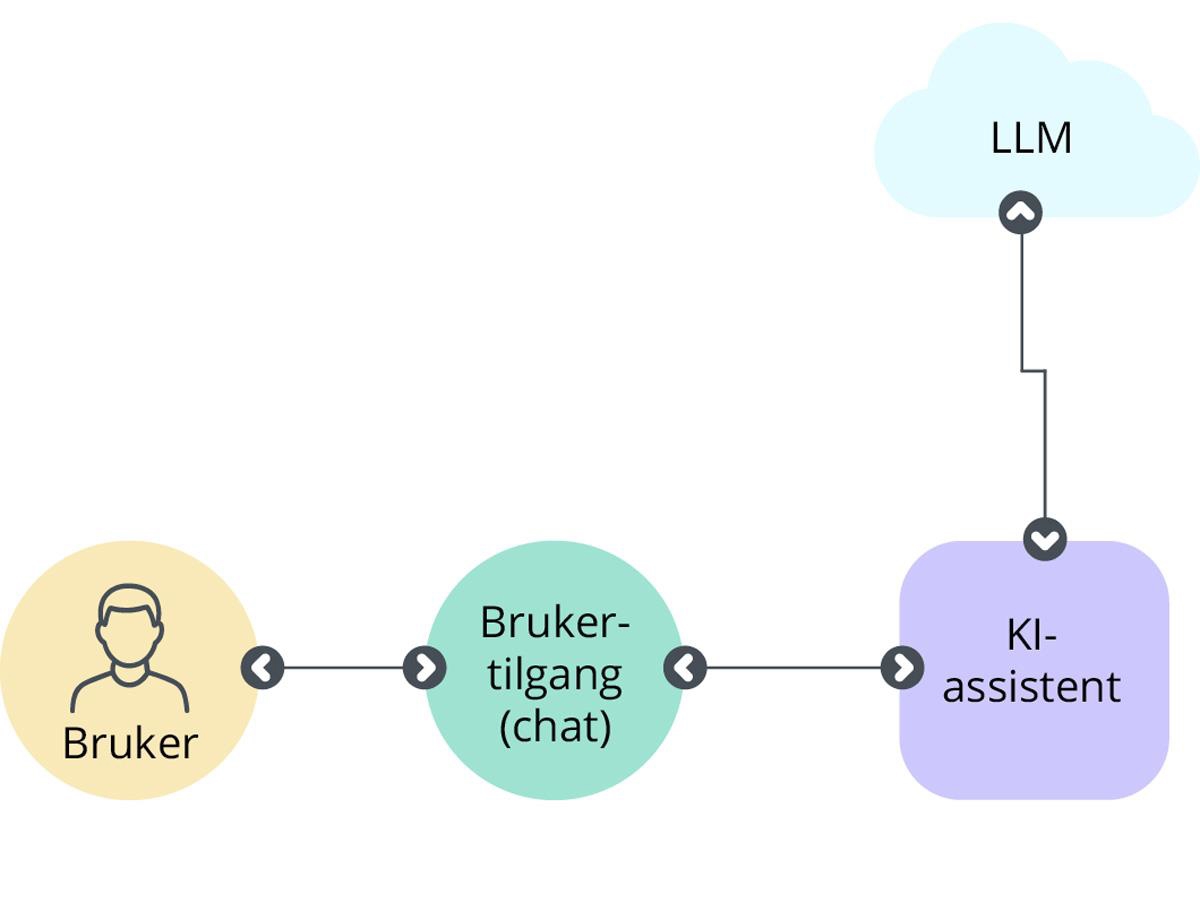
De fleste virksomheter som har innført KI-assistenter basert på generativ KI og store språkmodeller har valgt en skybasert løsning. Arkitekturen for en slik løsning er svært enkel, og man trenger strengt tatt ikke koble til egen systemarkitektur. Se Figur 4.
Brukerne samhandler med KI-assistenten gjennom f.eks. en chatbot eller et annet brukergrensesnitt. Deretter sendes meldingen til KI-assistenten som kaller opp den skybaserte språkmodellen (LLM) for å forstå hva brukeren ønsker. Dersom man ikke har gjort noen tilpasninger til egne systemer vil språkmodellen svare på forespørselen. I dette tilfellet vil da både brukertilgang og selve KI-assistenten normalt være skybasert og levert av KI-systemleverandøren. Dersom selve språkmodellen hostes som en skytjeneste (noe som er vanlig) bør man være ekstra nøye på å sjekke databehandleravtalen som gjelder for tjenesten og om dataflyt utenfor EU/EØS området er i tråd med de strenge overføringsreglene etter personvernforordningen.
Figur 4 Nivå 1 – Systemarkitektur
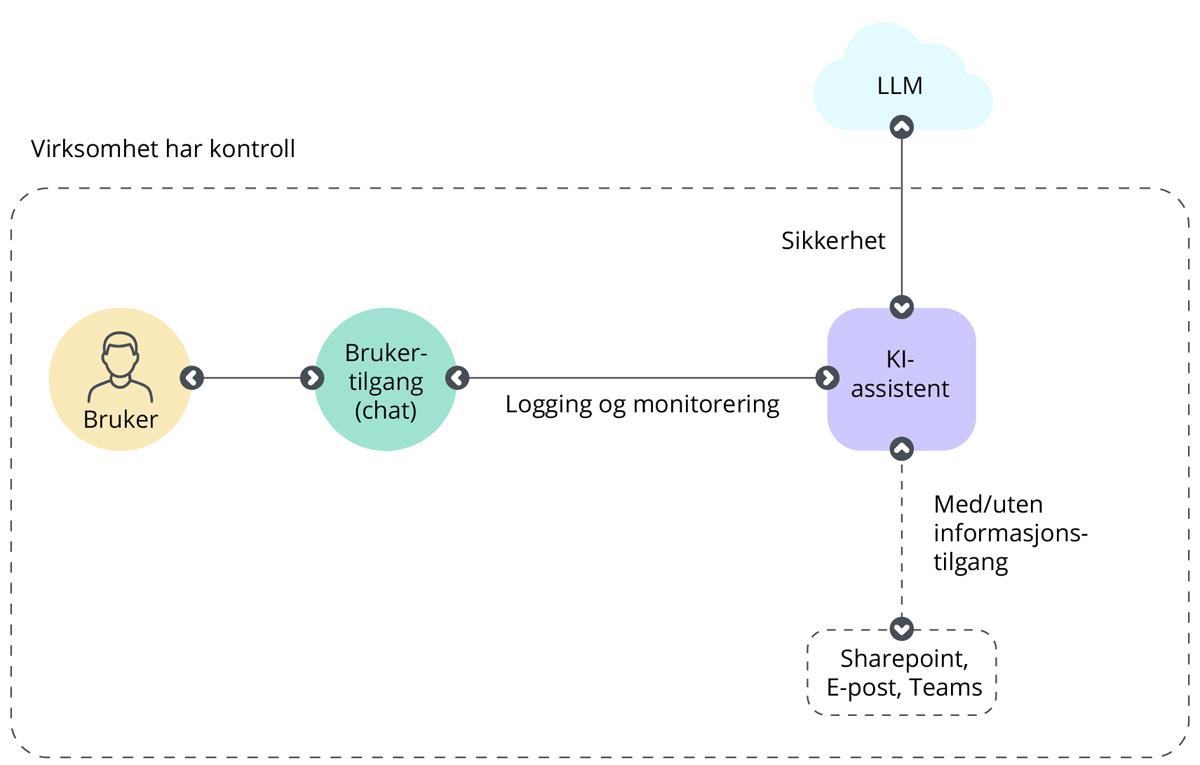
Også virksomheter som har integrert KI-assistenter med egne data (fra egen skyinfrastruktur), og som en del av egne løsninger bruker ofte skybaserte løsninger for selve KI-assistenten og den underliggende språkmodellen. Dette er det vi har kalt nivå 2 i resten av rapporten, og KI-assistenten blir da betydelig mer integrert med selskapets egen IT-infrastruktur. Se Figur 5
Figur 5 Nivå 2 – Systemarkitektur
Dersom man ønsker kontroll med hvilke data språkmodellen bruker for å svare, kan man styre dette gjennom å peke til de dokumentene man henter kontekst fra. Disse dokumentene brukes ikke til å trene selve språkmodellen, kun som innholdselementer for å gi kontekst til svarene. Språkmodellen brukes da først til å tolke instruksen og formulere et søk, for deretter for å generere et svar fra de returnerte dokumentene. En måte å gjøre dette på er gjennom RAG (Retrieval-Augmented Generation), der dokumentene ligger i egne indekserte databaser. Andre alternativer er KAG (Knowledge Graph-Augmented Generation) hvis dataene hentes fra kunnskapsgrafer og CAG (Cached-Augmented Generation) hvis relevante data legges i minnet før assistenten behandler instruksene.
For å få full nytte av mulighetene til en KI-assistent kan det også være hensiktsmessig å integrere KI-systemet (og svarene/anbefalingene som genereres) med selskapets interne systemer. Dette skjer oftest via an API Gateway der leverandørene av de interne systemene har kunnskapen om hvordan dette integreres i praksis.
En annen fordel med å integrere KI-assistenten i egen virksomhetsarkitektur er at all kommunikasjon skjer innenfor selskapets egne sikkerhets- og logglag for autentisering, kryptering og overvåkning.
Til sist er det mulig å justere på selve språkmodellen og bygge den ut med mer spissede innholdsdokumenter eller tilpasse den til å løse bestemte oppgaver. Dette kalles finjustering, og gjør at språkmodellen oppfører seg slik man ønsker samtidig som man bruker kraften i en pretrent LLM. Utbygging med mer data (dvs. videre forhåndstrening) gir mer kontroll over hvilke data modellen trenes på, og kan være hensiktsmessig dersom man har helt spesifikke krav til full datasuverenitet, dekning av fagspråk og bransje-sjargong (f.eks. jus, medisin), minoritetsspråk (f.eks. samisk), har ekstreme krav til rask respons eller ser på det som en mulighet til å utvikle tilpassede løsninger for videresalg. Tilpasning (dvs. finjustering) gjøres ved at domeneeksperter lager et separat datasett som viser hvordan en type oppgaver (f.eks. sammendragsgenerering og referatskriving) skal løses av språkmodellen. Figur 6 viser skissemessig hvordan systemarkitekturen for en tilpasset modell (nivå 3) kan se ut.
Figur 6 Nivå 3 – Systemarkitektur
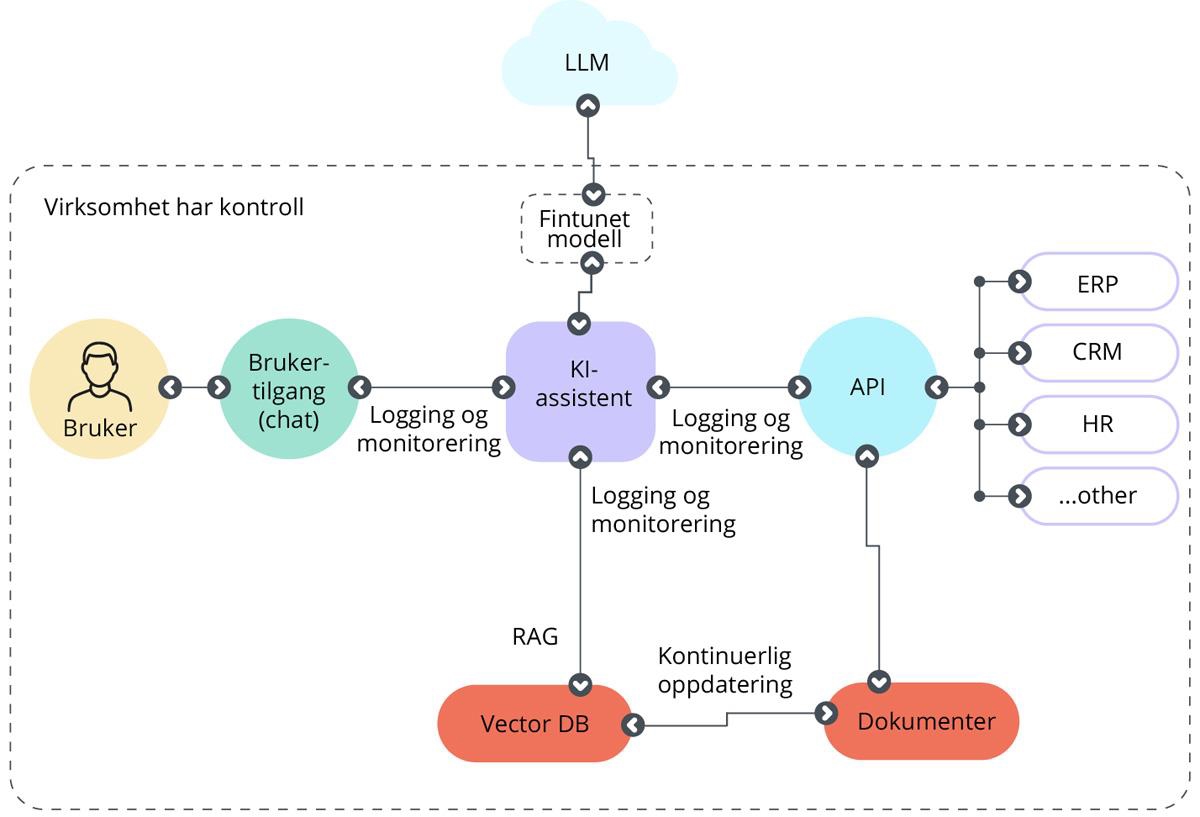
Merk at å videre pretrene eller finjustere en eksisterende språkmodeller svært kostbart, krever spesialkompetanse og tilpasset arkitektur. De fleste norske virksomheter klarer seg utmerket med finjustering eller RAG på åpne modeller, så denne løsningen vil ikke bli beskrevet nærmere i denne veilederen.
Virksomheter som allerede har en etablert skyplattform eller skytjeneste har en fordel når man skal ta i bruk KI-assistenter. Ofte vil virksomhetene velge KI-assistent fra samme leverandør som man allerede har avtaler med, og kjøper andre tjenester fra. Ønsker man for eksempel KI-assistent programvare integrert i kontorstøtteverktøy fra Microsoft eller Google, må man også bruke utviklingsverktøy fra samme selskap.
Skyleverandørene tilbyr ulike typer verktøy og løsninger for både å tilpasse KI-assistenter til eget bruk, integrere i virksomhetens systemer og for å finjustere eller pretrene egne modeller.
Tabellen angitt i kapittel 2 oppsummerer de ulike modellnivåene (fra åpen, via integrert til tilpasset), med indikasjon på hva de er egnet til, hvilket problem de løser og hva som kjennetegner dem.
Bruk den som en indikasjon til å velge hvilken modell som passer for bedriften.
5.3 Loggføring og sporbarhet
Loggføring av interaksjoner med KI-assistenter kan være viktig for å sikre sporbarhet, avdekke feil og håndtere misbruk – særlig i sensitive kontekster.
Samtidig reiser loggføring personvernmessige spørsmål, ettersom loggene i praksis kan brukes til å spore individers adferd, preferanser eller sårbare forhold.
Det er derfor sentralt å vurdere nøye hva som skal logges, hvorfor, hvilke personopplysninger som inngår, og hvordan loggene skal brukes. Formålene med loggføringen må være klart definerte og nødvendige, og det bør vurderes om loggingen krever et behandlingsgrunnlag etter personvernforordningen.
I tillegg må det tas stilling til hvor lenge loggene skal oppbevares, hvem som skal ha tilgang, og hvordan informasjonssikkerheten skal ivaretas. Uten slike avklaringer kan loggføring bidra til utilsiktet overvåking eller brudd på den registrertes rettigheter.
5.4 Systemkostnader
Etter hvert som man beveger seg opp i nivå på KI-assistenter, vil også systemkostnadene øke. Tabell 9 gir en indikasjon på hvordan ulike systemrelaterte kostnader endrer seg med økende KI-assistent nivå
Tabell 10 Systemkostnader ved valg av KI-assistent nivå
|
Kostnadspost |
Typiske elementer |
KI-assistentnivå |
||
|---|---|---|---|---|
|
1 - Åpen |
2 - Integrert |
3 - Tilpasset |
||
|
Lisens |
|
● |
●● |
●● |
|
Token-forbruk* |
|
● |
●● |
●●● |
|
RAG-infrastruktur |
|
○ |
○ |
●● |
|
Beregningskapasitet |
|
○ |
○ |
●● |
|
Dataanskaffelse & rensing |
|
○ |
● |
●●● |
|
Utvikling & integrasjonsarbeid |
|
○ |
● |
●●● |
|
Sikkerhet & compliance |
|
○ |
● |
●●● |
|
Support & endringsledelse |
|
● |
●● |
●●● |
|
Symbol |
Forklaring |
|---|---|
|
○ |
Lav eller ubetydelig kostnad |
|
● |
Begrenset kostnad |
|
●● |
Betydelig kostnad |
|
●●● |
Svært høy kostnad, krever ofte egne kost-nyttevurderinger for å forsvare |
* Se definisjon for Token i Vedlegg A – Ord og begrepsliste