2 Er hensikten med å innføre en KI-assistent klar?
2.1 Innledning
Dette kapittelet viser på en praktisk måte hvordan dere kan gå fra løse idéer til et tydelig, håndterbart prosjektmandat. Samtidig hjelper det deg å luke ut bruksområder som ikke gir nok verdi på et tidlig tidspunkt i reisen.
Erfaring viser at et vellykket KI‑prosjekt aldri starter med spørsmålet «Hvilken modell skal vi bruke?» Det starter med «Hvor trykker skoen?». Det dere gjør her bestemmer hvor dyr, lang og risikabel resten av reisen blir. Bruk derfor nok tid på å bli enige om hvorfor dere skal ta i bruk en KI‑assistent eller ‑agent, hva den skal løse, og hvem som blir påvirket.
Husk også at i offentlig sektor er behovs- og kompetansefasen anbefalt i prosjektveiviseren fra Digdir 1 .
Jo klarere problemet og suksesskriteriene beskrives i dette stadiet av beslutningsprosessen, desto enklere blir anskaffelser, risikovurderinger og gevinstrealisering senere.
Som hjelp til å finne egnet nivå på KI-assistenten har vi også med et kapittel som omhandler hvilke ulike typer som finnes, hva de er best egnet til, og hva man bør ta høyde for ved innføring og bruk.
Til sist i dette kapittelet sier vi litt om hvordan dere kan klassifisere dataene som skal brukes av en KI-assistent med tanke på risiko, og gir en indikasjon på hva som er lov å gjøre med data av ulike typer og risikoklasser.
2.2 Hva ønsker du å oppnå ved bruk av KI
For å ende opp med å bruke gode, verdiskapende KI-assistenter eller KI-agenter er det flere ting som må vurderes i sammenheng. Det er derfor viktig å tenke gjennom hele prosessen og gjøre seg kjent med relevante vurderinger som må gjøres underveis, før innføringen av en KI-assistent kan starte.
Selv ved kjøp av en lisens til en av de åpne KI-assistentene som finnes, bør man tenke gjennom hva man vil bruke den til, hvilken effekt det har at man bruker den, hvilken kompetanse man trenger, og hva som skjer om man ikke lykkes (eller at nytten ikke var så stor som man hadde tenkt).
Prosessen kan deles i tre faser, med et sett vurderinger for hver fase:
2.2.1 Hvorfor ønsker dere å ta i bruk KI-assistenter?
Dette høres ut som et enkelt spørsmål, men det forutsetter kunnskap om tre faktorer:
- For det første en grunnleggende forståelse av hvilken verdi dere skaper, for hvem, og hvordan dere jobber. Dette danner grunnlaget for de faktiske brukerbehovene KI-assistenten skal møte.
- Det neste er en god forståelse av hva som er mulig å få til med en KI-assistent. Denne veilederen vil hjelpe deg med det, men dersom du er ukjent med KI-assistenter, anbefaler vi å bruke litt tid på å forstå hvordan de virker, hvilke ulike typer som finnes, hva som kjennetegner dem og hvilke begrensninger de har.
- Til sist må dere gjøre noen antakelser av hvilken verdi KI vil skape, for hvem, og hvilke begrensninger som gjelder. Ikke tro at KI vil endre på «alt», men vær så presis som mulig med tanke på hva dere ønsker å oppnå. Vær forberedt på å gå tilbake til denne vurderingen flere ganger i prosessen. Veldig ofte vil man finne verdi på andre områder enn de man startet ut med.
Tenk stort, men start smått. Svar med en klar setning på hvorfor dere vil prøve KI akkurat nå. Kanskje er målet bare å gi ansatte en smaksprøve, teste om teknologien faktisk løser et konkret behov, eller legge grunnlaget for en helt ny KI-drevet forretningsmodell. Uansett ambisjonsnivå er poenget å gjøre hensikten tydelig for dere selv. Den kan justeres underveis etter hvert som dere lærer mer, så ikke gjør startfasen mer komplisert enn nødvendig.
2.2.2 Hva må på plass for å innføre teknologien i organisasjonen?
Her er det flere forhold som må vurderes i lys av hva KI skal brukes til. Vurderingene knytter seg til hvilke roller og ansvar som må på plass, hvilke data som skal behandles og genereres, overholdelse av relevant lovverk, valg av teknisk infrastruktur, rett kompetanse og hvordan man sikrer at løsningen fungerer når den innføres.
I denne fasen må man også sjekke at man faktisk får den verdien man hadde ønsket. Om verdien og ønsket effekt uteblir, se på vurderingene på nytt. Kanskje dere må revurdere forventningene, eller juster måten KI-assistenten brukes.
2.2.3 Hvordan holdes KI-løsningen levende og trygg?
Når assistenten skal inn i daglig bruk, må den integreres i arbeidsprosessen og forvaltes som et levende produkt og ikke som et engangsprosjekt. Som med andre endringsprosesser, må også bruk av KI inn i virksomhetens handlingsplaner. Det kan være årshjul, KPIer, strategioppdateringer, budsjetter, risikovurderinger, opplæring og gevinstevalueringer. For å holde fokus kan det være en god ide og utpeke en person i ledelsen som følger innføringen:
- Overvåk ytelse og risiko. Mål svarkvalitet, kostnad og brukertilfredshet jevnlig (f.eks. månedlig). Logg avvik og driftshendelser etter samme prinsipp som andre IT-systemer.
- Oppdater datagrunnlag og modell. Dersom dere bruker egne data, planlegg jevnlige (f.eks. kvartalsvis) evalueringer av om datagrunnlaget fortsatt er relevant for modellen.
- Kontroller samsvar med regelverk. Bruken av løsningen vil ofte endre seg over tid, så sjekk jevnlig (f.eks. halvårlig) samsvar med gjeldende personvernkrav, KI-forordningen, sikkerhetsloven, andre gjeldende lovkrav for din sektor/bransje og interne retningslinjer.
- Bygg kompetanse og ferdigheter. Etter hvert som bruken brer om seg og nye brukere kommer til, sett av tid til nye brukerkurs, superbruker-forum og idé-workshops. Fang opp nye behov og beslutt om assistenten skal utvides – eller skaleres ned hvis gevinsten uteblir.
Tenk på KI-assistenten som en løsning dere gir jevnlig service: en ansvarlig person, et par enkle måltall og faste «helsesjekker».
2.3 Avgrens omfanget
Å etablere klare avgrensninger tidlig i prosessen bidrar til en mer vellykket innføring av teknologien. Det er fire sentrale områder som virksomheten tidlig bør ta stilling til:
Personvern : Vurder om bruken av en KI-assistent innebærer behandling av personopplysninger. Hvis dette er tilfelle, må det vurderes hvilke personvernkrav som gjelder – for eksempel kan en vurdering av personvernkonsekvenser være nødvendig. Dette må planlegges allerede i behovsfasen for å sikre etterlevelse og unngå forsinkelser i senere faser (se kapittel 4.3).
For en enklere tilnærming: sørg for at personopplysninger ikke brukes i input eller kan inngå i output.
Autonomi : Vurder om virksomheten trenger en KI-assistent som gir beslutningsstøtte, eller en KI-agent som utfører autonome handlinger. Valget påvirker risikoklassifiseringen under KI-forordningen og setter krav til dokumentasjon og testing. Det er viktig å ha avklart dette tidlig, slik at virksomheten kan planlegge riktig risikohåndtering og ressursbruk (se kapittel 4.2).
For en enklere tilnærming: sørg for at et menneske alltid har siste ord før resultatet brukes videre.
Data-tilgang : Vurder hvilke data KI-assistenten skal ha tilgang til. Start prosjektet med lese-tilgang til et begrenset og definert dokumentsett. Dette gir god kontroll over hvilke data KI-assistenten får tilgang til og forhindrer «scope creep» – altså at omfanget gradvis utvides uten at dette er godt nok vurdert eller planlagt. Etter at en avgrenset pilotfase er gjennomført og evaluert som vellykket, kan man deretter eventuelt utvide med flere datakilder.
For en enklere tilnærming: begrens KI-assistentens tilgang til virksomhetens data.
Tidsramme : Sett en fast tidsperiode for behovsfasen og vær disiplinert med å holde fristen. Erfaringsmessig har små og mellomstore virksomheter hatt størst suksess med behovsfasen når de setter av 3 til 4 uker, mens større virksomheter gjerne trenger opptil 6 uker. Lengre tidsrammer kan føre til redusert engasjement og interesse rundt prosjektet.
Ved å ha tydelige avgrensninger på disse områdene sikrer virksomheten en effektiv, realistisk og målrettet prosess for innføring av KI-assistenter.
2.4 Definer målgruppen
Å vite hvem KI-assistenten skal hjelpe, er like avgjørende som å vite hva den skal gjøre. En klar målgruppevurdering legger grunnlaget for riktige prioriteringer, tydelige forventninger og reell medvirkning.
Det viktigste skillet er om KI-assistenten skal betjene interne eller eksterne brukere.
Tabell 1 Målgrupper
|
Interne brukere |
Eksterne brukere |
|
|---|---|---|
|
Typiske grupper |
Alle ansatte og ledere |
Innbyggere, kunder, leverandører og partnere |
|
Primær verdi |
Effektivitet, beslutningsstøtte og kvalitets-økning |
Bedre tjenesteopplevelse, selvbetjening, tilgjengelighet |
|
Suksesskriterier |
Lav terskel i hverdagen, integrasjon mot eksisterende verktøy, kompetanseheving |
Enkelt språk, universell utforming, åpenhet om datakilder, få feil svar, tillit og trygghet |
I starten av prosessen anbefales det å begynne med en bestemt og avgrenset målgruppe og heller utvide omfanget senere.
Kartlegg interessenter og be om innspill fra alle som er direkte eller indirekte berørt ved innføring av et KI-system, spesielt dersom det treffer parter som ikke bruker løsningen selv.
2.5 Oversikt over ulike typer KI-assistenter og hva de er nyttige for
Det finnes i dag mange forskjellige KI-assistenter, og det kan være krevende å vite hva man skal velge. Et nyttig utgangspunkt er å vurdere hvor stort behov man har for kontroll over dataene som brukes og svarene som genereres, og hvordan assistenten er koblet til virksomhetens systemer. Dette påvirker både hvilken nytte man kan forvente, og hvilke krav som stilles til ansvar, kompetanse og teknisk infrastruktur.
Start med å vurdere hvilket problem som skal løses: Trenger man kun et generelt skriveverktøy, eller skal assistenten jobbe sammen med virksomhetens spesifikke data, systemer og prosesser? I det følgende beskrives ulike typer løsninger, og hva slags behov de typisk dekker. Vi indikerer også når det kan være aktuelt å ta steget videre til en mer bedriftstilpasset løsning.
I denne veilederen brukes tre nivåer av KI-Assistenter.
Modellene på åpne plattformer er oftest de første en virksomhet tar i bruk. Enhver som oppretter en bruker hos en av leverandørene kan enkelt få tilgang, og disse finnes ofte i både gratisversjoner og betalte versjoner med mer funksjonalitet. Merk at mange bedrifter har restriksjoner på bruk av modeller på åpne plattformer.
Det neste nivået assistenter er modeller som er integrert med bedriftens eget IT-miljø. Dette gir mulighet til å bruke KI-assistenter og samtidig ha kontroll på hvilke data som brukes av modellen og hvordan instrukser og resultater lagres.
Det tredje nivået er for bedrifter som har behov for mer tilpassede løsninger, f.eks. for å støtte helt bestemte arbeidsprosesser, behov for å sikre at kun forhåndsdefinerte data brukes som kunnskapsgrunnlag av modellen, eller behov for å tilpasse språket KI-assistenten bruker.
Merk at flere av de store leverandørene, som f.eks. Microsoft, tilbyr KI-assistenter på tvers av nivåene – fra åpne modeller via Copilot i nettleseren, til integrerte løsninger i Microsoft 365, og videre til skreddersydde assistenter i Azure OpenAI.
Figur 1 i avsnitt 2.5.5 viser en skjematisk oversikt over de ulike modellnivåene, og Tabell 2 oppsummerer de viktigste egenskapene ved hver av dem. Jo høyere opp i nivå man beveger seg, spesielt fra nivå 2 til 3, jo større er behovet for gode styringssystemer rundt KI-assistenten.
Tabell 2 Oversikt over KI-assistent nivå
|
Nivå |
Beskrivelse |
Typisk bruk |
Fordel |
|---|---|---|---|
|
1. KI-assistent på åpen plattform |
Gratis/abonnementstjeneste på nett (ChatGPT, Claude) |
Idégenerering, skrivehjelp, prøve ut KI |
Lav terskel – kom i gang på minutter |
|
2. KI-assistent integrert i eget IT-miljø |
Integrert i eget IT-miljø, uten eller med søk i egne filer (Copilot Chat/Copilot 365) |
Tekstforbedring, e-postutkast, enkel analyse for hele teamet |
Trygt miljø – data blir på jobbens konto |
|
3. Tilpasset KI-assistent |
Bygget eller tilpasset for egne prosesser, data eller terminologi/språk |
Intern brukerstøtte, saksarkiv-søk, bransjespesifikke rutiner |
Presis og tilpasset – løser akkurat deres oppgave |
2.5.1 Nivå 1 – KI-assistent på åpen plattform
Dette er tjenester som ChatGPT eller Claude (det finnes også veldig mange andre) som du åpner i nettleseren uten å koble dem til interne systemer.
Fordelen er at de muliggjør lynrask oppstart, lav eller ingen kostnad og ingen krav til IT-drift. De er tilgjengelige for alle som vil prøve, idémyldre og pusse på tekst i løpet av få minutter. De kan svare på alt – bokstavelig talt – selv om de ikke nødvendigvis vet svaret. De åpne KI-assistentene brukes ofte som støtte til enkeltpersoner og i startfasen når man gjør seg kjent med mulighetene.
Ulempen med slike verktøy er at du må holde konfidensiell informasjon unna – alt du skriver eller laster opp kan i prinsippet lagres eksternt og brukes til videre trening av modellene 2 . Juridisk er risikoen moderat så lenge du unngår person- eller forretningskritiske data, men det er lett å trå feil fordi plattformen ikke «vet» hva som er hemmelig. Disse verktøyene passer derfor best til utforsking, inspirasjon og individuell skrivehjelp.
Når en virksomhet åpner opp for at ansatte kan ta i bruk åpne assistenter, er det viktig å gi alle ansatte nok kunnskap og ferdigheter til å bruke dem riktig, se f.eks. kapittel 3.4.3 for enkle tips om dette. Det er også hensiktsmessig å etablere klare rutiner for hva som kan og ikke kan deles med KI-assistenten.
Tre enkel kjøreregler kan være:
- Ikke del sensitiv informasjon: Legg aldri inn personopplysninger, fortrolig forretningsinformasjon eller andre beskyttede data i åpne eller usikrede KI-tjenester.
- Anbefalte KI-verktøy: Bruk kun KI-assistenter og andre KI-baserte verktøy som organisasjonen anbefaler.
- Del kun nødvendig informasjon: Begrens deling av data til det som er nødvendig for formålet. Anonymiser eller bruk fiktive data der det er mulig.
Sjekk svarene: Dersom svarene fra KI-assistenten skal brukes videre, vær nøye med å sjekke riktigheten av informasjonen som gis, f.eks. ved å be om referanser (som også må verifiseres), og be KI-assistenten beskrive hvordan den kom frem til svaret.
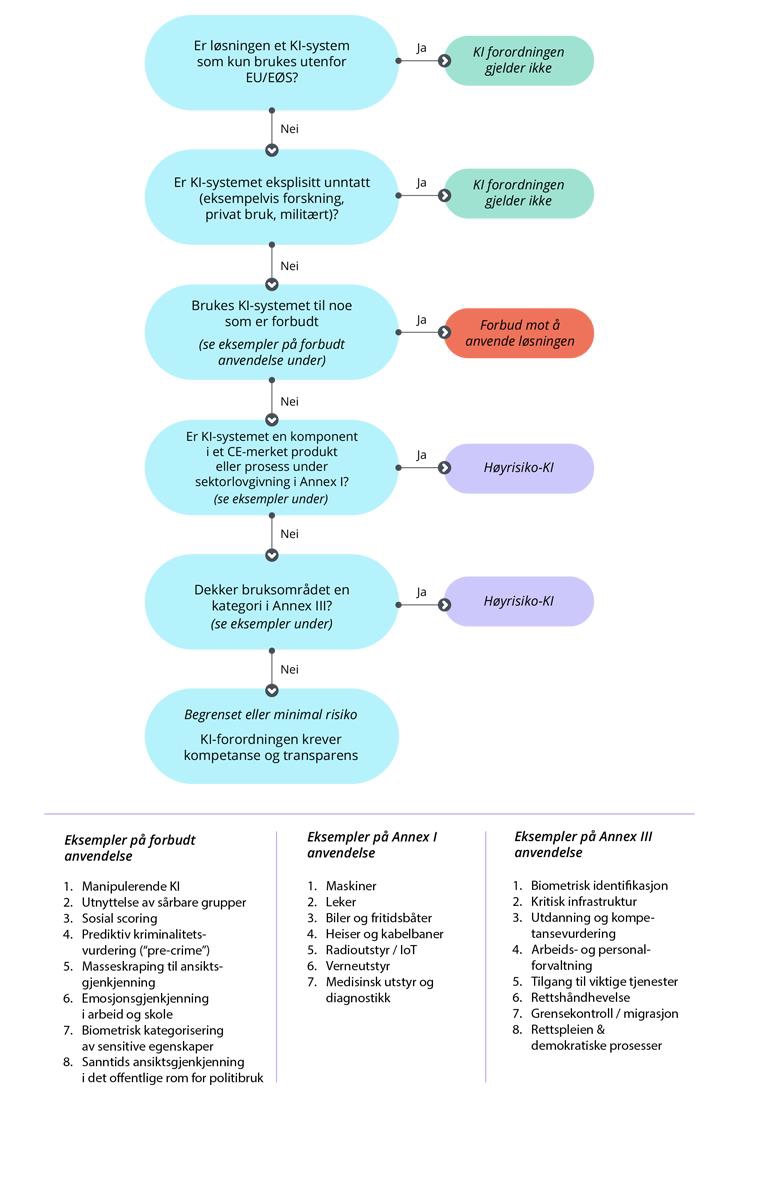
For mer informasjon om hvordan man kan kategorisere kritisk informasjon, behandle sensitive data, og undersøke om anvendelsen omfattes av den kommende KI-forordningen, se kapittel 4
2.5.2 Nivå 2 – KI-assistent integrert i eget IT-miljø
Vi skiller mellom to ulike anvendelsesområder når en KI-assistent integreres i bedriftens eget IT-miljø.
I den første varianten kjøper du en ferdig KI-assistent som ligger inne i f.eks. Microsoft Edge, Google Workspace, eller som leveres som selvstendig tjeneste fra ulike norske og internasjonale tilbydere. Selve språkmodellene er de samme som brukes av de åpne KI-assistentene, men trafikken går via virksomhetens egen infrastruktur, med pålogging, logging og mulighet til å stenge av funksjoner. Dermed slipper du datalekkasjer og får én felles lisenskostnad i stedet for mange enkeltabonnementer.
Begrensningen er at assistenten fortsatt ikke ser interne dokumenter, så svarene ligner dem du får i den åpne løsningen beskrevet over.
Denne varianten egner seg når medarbeiderne trenger et trygt rom for idé- og skrivearbeid, men før dere åpner KI-assistenten for forretningskritisk innhold.
En litt mer integrert modell er f.eks «Copilot 365»-varianten. Den har mer eller mindre samme brukeropplevelse som KI-assistenten beskrevet over, men dersom man bruker Microsoft 365, får KI-assistenten tilgang til e-postkonto, Teams, SharePoint og OneDrive, samt at KI-assistenten integreres direkte i kontorstøtteverktøyene.
KI-assistenten kan da skrive møtereferater, oppsummere lange e-posttråder eller hente gamle presentasjoner når du ber om dem. En slik løsning krever god dataklassifisering og en viss «orden i eget hus» - gamle, dupliserte eller feilaktige filer gir dårlig svar, og sensitive mapper må skjermes. Lisensen er dyrere og IT må sette opp indeksering og tilgangsregler, men utviklere og spesialister på maskinlæring er fortsatt ikke nødvendig. En KI-assistent integrert med bedriftens eget filsystem er ofte en god match for virksomheter som vil heve produktiviteten bredt uten å starte et KI-prosjekt fra bunnen av.
Virksomheter som tar i bruk slike integrerte KI-assistenter er selv ansvarlig for å sikre lovlig og ansvarlig bruk. Hver implementering krever en individuell vurdering. Dette innebærer blant annet å sette seg inn i teknisk dokumentasjon og informasjon fra leverandøren, kontrollere hvilke formelle forpliktelser og ansvarsforhold som følger av inngåtte avtaler, og vurdere hvorvidt løsningen behandler personopplysninger eller annen sensitiv informasjon. Vedlegg C inneholder mer inngående informasjon om hvordan man kan adressere disse vurderingene.
Halden kommune implementerte en enkel standard «Personlig KI-assistent» løsning for alle sine ansatte. Løsningen gir alle ansatte tilgang til et personlig chat-grensesnitt, hvor de har mulighet til å velge mellom flere underliggende språkmodeller, og hvor de kan laste opp dokumenter i et trygt miljø. Løsningen er levert som en tjeneste gjennom et norsk teknologiselskap, og er fullt integrert i kommunens egen IT-infrastruktur med trygg lagring og kontroll. Dette sikrer at all databehandling skjer internt og i tråd med lover og retningslinjer. Denne løsningen har gjort at Halden kommune på kort tid og med relativt lave kostnader har kunnet innføre et brukervennlig KI-verktøy for alle ansatte, slik at flest mulig kan komme i gang og bidra til videre bruk og utvikling av KI-løsninger.
Modell nivå 2
Equinor har innført en standard chatbot som assistent for alle ansatte, med språkmodeller fra Microsoft/OpenAI. EquinorChat er satt opp i eget IT-miljø for å ivareta streng informasjonssikkerhet og kontroll på lagring og deling (som da skjer innenfor EU). Selskapet jobber systematisk med klassifisering av sensitivitet i ulike data, og har klare grenser på hva som kan legges inn i chatboten. Løsningen har 9000 unike brukere hver måned, som i snitt melder om besparelser i sitt arbeid på 1-3 timer per uke. Equinor utvikler og tar i bruk flere KI-løsninger for å støtte spesifikke funksjoner og spesialister, men ønsker med EquinorChat at så mange som mulig skal få erfaring med KI for å kunne være med på utviklingen.
Modell nivå 2
2.5.3 Nivå 3 – Tilpasset KI-assistent
Det er i prinsippet ingen grenser for hvilke tilpasninger som kan gjøres av en KI-assistent for å få den til å virke best mulig i en virksomhet, men for oversiktens skyld deler vi tilpassede KI-assistenter inn i tre kategorier
- KI-assistent for støtte til en avgrenset oppgave.
- KI-assistent med kontrollert datatilgang.
- KI-assistent med finjustert språkmodell.
KI-assistenter som støtter en avgrenset oppgave er tilpasset og instruert spesielt til formålet, som kan eksempelvis være intern brukerstøtte, støtte til HR-spørsmål, prosjektplanlegging, eller kundeservice. Bedriften bestemmer dialogflyt, tillatte informasjonskilder, hvilke svar som er «fasit», og ikke minst hva modellen ikke skal svare på.
Fordelen er god kontroll og rask utvikling uten tunge kodeprosjekter; to–tre personer kan ha en prototype oppe på dager eller uker. Begrensningen er at assistenten ikke kan brukes på alt mulig – den gjør akkurat det den er programmert for. Kostnaden ligger i konsulentbistand og interne timer, og i mindre grad i lisens eller infrastruktur.
Solcellespesialisten har innført fem ulike tilpassede KI-assistenter som hjelper til med alt fra offentlige anbud, reklamasjonshåndtering, software-koding, utvikling og analyse av underleverandører. Løsningene sparer tid og øker kvalitet i leveransene. Assistentene er satt opp med lavkode-verktøy, med definering av funksjonalitet og instruksjoner som gir kontekst og avgrensninger til hvordan assistentens oppgaver utføres. Gjennom arbeidet med KI-assistenter har Solcellespesialisten samtidig jobbet systematisk med å rydde og kategorisere i fagsystemer og datastrømmer, som igjen åpner for nye anvendelser.
Modell-nivå 3
For en KI-assistent med kontrollert datatilgang kombineres en språkmodell med et eget søke- og gjenfinningslag som slår opp i virksomhetens dokumenter i sanntid. Det betyr at svaret baserer seg på ferske filer, saksarkiv eller håndbøker, uten behov for å re-trene selve modellen. Et eksempel på slik teknologi er såkalte RAG-løsninger (Retrieval-augmented generation).
Kristiansund kommune piloterer Påkobla Assistent, en avansert KI-assistent for saksbehandling i offentlig sektor. Assistenten er trent på kommunens egne vedtak, planer, saksutredninger og rutiner, og skal brukes aktivt av ansatte på tvers av fagområder for å effektivisere og kvalitetssikre forvaltningen. Påkobla Assistent er bygget med sikkerhetsnivå 4 på ID-porten, og kjører i Microsoft Azure. Løsningen benytter RAG og er integrert med kommunens fagsystemer og dokumentarkiv. Dokumentasjon og informasjon konverteres umiddelbart til strukturerte datasett som legges til i RAG, slik at kommunen kan bruke egne data nærmest i sanntid. Assistenten skal brukes til å veilede både ansatte og innbyggere i komplekse spørsmål.
Modell-nivå 3
Resultatet er oppdaterte, kildebelagte svar – avgjørende for bruk i kunnskapstunge miljøer – og mindre hallusinasjoner. Ulempene er mer kompleks drift: dere må bygge og drifte søkeindeks, håndtere versjoner og sikre at kun person med riktige rettigheter får se svar som baserer seg på dokumenter med tilgangskontroll. For å få en slik løsning til å fungere trengs det typisk dataingeniører eller eksterne partnere, samt juridiske vurderinger av personvern og arkivlov når kritiske og rettighetsbelagte dokumenter eksponeres via KI-assistenten.
En KI-assistent med finjustert språkmodell innebærer at dere trener selve språkmodellen videre med virksomhetens historikk, fagspråk og eksempler. En slik tilnærming er nyttig for veldig spesifikke anvendelser som krever full kontroll over både hvilke data modellen baserer svarene på, og hvordan den svarer (dette må ikke forveksles med å bygge en egen språkmodell – se Nivå 4).
DNVs DATE-system (Direct Access to Technical Experts) inkluderer flere KI-agenter som støtter DNVs eksperter i behandling av tekniske henvendelser fra kunder. Kundehenvendelser rutes automatisk til riktig organisasjonsenhet, og spørsmål og vedlegg oppsummeres med identifikasjon av viktig informasjon. Saksbehandlere har rask tilgang til liknende saker, og kan generere utkast til svar basert på et brukerstyrt utvalg av disse. KI-agenten agerer på noen områder på egen hånd innenfor definerte rammer. DNV har inkludert flere «sikkerhetsbarrierer» som krever at brukeren gjør bevisste valg underveis i saksbehandlingen, og guider agenten underveis i svar-generering. Det er eksperten som godkjenner svaret før det sendes. DATE med tilhørende data og bruk er basis for videre kunnskapsforvaltning i DNV.
Modell-nivå 3
Eksempler er KI-assistenter som kan skrive pasientjournaler, tolke forsikringsvilkår eller kode i virksomhetens egen plattform med langt høyere presisjon enn standardmodellene. Frihetsgraden er stor, men det er også regningen: egne GPU-servere eller skyøkter, drifts- og kvalitetsrutiner for KI-modeller, datarensing og kontinuerlig overvåking for bias og sikkerhet, samt flere domeneeksperter og fageksperter som skal lage datasettene som modellen skal finjusteres med.
I tillegg utløses strengere krav i KI-forordningen hvis løsningen faller i høyrisiko-kategorien. Denne løsningen velges kun når verdien av domenetilpasset intelligens – eller regulatorisk plikt – klart overstiger kostnadene.
Som en ytterligere raffinering av en finjustert modell, kan en virksomhet også bygge en selvhostet open-source grunnmodell som et alternativ der full driftkontroll er kritisk, men som fortsatt bygger videre på en eksisterende modell. Denne varianten beskrives ikke nærmere i denne veilederen.
2.5.4 Nivå 4 – Suveren grunnmodell fra bunnen av
En grunnmodell bygges ved at en virksomhet samler inn petabyte-skala tekst, kode, lyd og /eller bilder, trener en helt ny språkmodell på egne superdatamaskiner og dermed eier fullstendig teknologi, IP og dataflyt.
Slike prosjekter handler ikke om bruk, men om utvikling, og krever milliardbudsjett, forsker- og ingeniørteam i hundretalls, kontinuerlig tilgang til kraftig maskinvare samt solide rutiner for etikk, sikkerhet, drift, kvalitet og juridisk etterlevelse på tvers av land.
I praksis er dette aktuelt kun for noen få svært store konsern, statlige etater eller internasjonale forsknings-/allianseprosjekter som trenger total kontroll over modellen (f.eks. for nasjonal sikkerhet, språkvern eller spesialiserte domener).
For de aller fleste norske virksomheter gir en suveren modell minimal ekstra nytte i forhold til kostnad og risiko; de vil oftest få større verdi ved å bygge videre på åpne eller kommersielle grunnmodeller og fokusere ressursene på tilpasning og datakvalitet.
Dette nivået er kun med for å komplettere beskrivelsen av KI-assistenter, og anses ikke som relevant for majoriteten av norske virksomheter, og inngår derfor ikke i resten av veilederen.
2.5.5 Oppsummering og eksempler
Når man beveger seg opp i nivå øker anvendelsesområdet, fra enkel chat til fagspesifikke løsninger. Samtidig stiger kompleksitet, kostnader og kompetansekrav betydelig fra ett nivå til det neste slik det er indikert i Figur 1. Velg derfor det laveste nivået som løser behovet ditt godt nok og oppgrader først når behovet endrer seg og gevinsten forsvarer mer investering.
Figur 1 Oversikt over ulike nivå av KI-assistenter brukt i denne veilederen
Det er ikke nødvendigvis slik at man må velge én bestemt type KI-assistent. Mange virksomheter vil over tid kombinere flere typer løsninger. For eksempel bruker mange en åpen eller integrert modell til generell kontorstøtte, samtidig som virksomheten bruker en mer tilpasset modell som støtte til bestemte arbeidsprosesser, og bruker en modell der KI-assistenten kun baserer svarene på helt spesifikke datasett.
Hotellkjeden Strawberry har utviklet sin egen-tilpassede kunnskapsassistent Scout hjelper ansatte i alt av daglige driftsgjøremål på tvers av funksjoner og avdelinger, og har gitt en effektiviseringsgevinst på 20 %. Assistenten trenes på interne håndbøker, retningslinjer og opplæringsmateriell, er bygget på toppen av skymiljøet, og knyttet til interne datakilder med en RAG-løsning. Planen er å utvide KI-assistenten til også å kunne utføre handlinger på vegne av ansatte og gjester (agentfunksjonalitet)
Modell nivå 3
Secure Practice har utviklet en KI-assistent som er integrert i kundetjenesten de tilbyr innen cybersikkerhet, og som automatiserer hvordan tjenesten leveres. Gjennom produktet MailRisk rutes potensielt skadelige e-poster automatisk fra kundens mail-systemer til analytikere i Secure Practice. KI-assistenten vurderer risiko for hver e-post og lager et sammendrag av innhold og risikovurdering, støtter analytikers vurderinger, samt sender rapport til kunden på en forståelig måte. Produktet og KI-assistenten er driftet i Microsoft Azure og er tett integrert med selskapets analyseplattform. All data fra tjenesten blir lagret av selskapet på datasenter i Norge i 90 dager før de slettes. Kundene kan selv slette egen data dersom de ønsker sletting før 90 dager. En slik løsning krever tydelige databehandleravtaler mellom kunde og leverandør.
Modell nivå 3
Sparebank 1 SMN har utviklet en KI-assistent som oppsummerer samtaler til kundesenteret. KI-assistenten transkriberer (oversetter fra tale til tekst) alle samtaler til kundesenteret, og lager samtidig automatisk en oppsummering av samtalen. Løsningen er integrert med bankens CRM-system, og oppsummeringene blir automatisk lagt i CRM-systemet når samtalen er avsluttet. Rådgiveren er ansvarlig for å lese gjennom, endre og godkjenne referatet fra samtalen. Løsningen har effektivisert kundesamtaler, og det har gitt høyere kvalitet i oppsummeringene og opplevd kvalitet for kunde. Løsningen ble lansert til alle rådgiverne i kundesenteret i Q1 2025, og har i løpet av første kvartal oppsummert 72 000 samtaler.
Modell nivå 3
2.6 Vær bevisst på hvilke data som brukes av KI-assistenten
Ulike typer data har ulik grad av sensitivitet og er underlagt forskjellige lover, regler og interne retningslinjer. I tillegg varierer risikoen knyttet til feil bruk, utilsiktet deling eller datalekkasjer betydelig. For å håndtere dette på en systematisk og forsvarlig måte, anbefales det å gjennomføre en dataklassifisering før data brukes i KI-sammenheng. For KI-assistenter som ikke har direkte tilgang til virksomhetens egne data vil dette innebære å etablere retningslinjer for hvilke data som kan brukes som input til assistenten.
Dataklassifiseringen bør ta utgangspunkt i to hoveddimensjoner: datatype og risiko/konsekvens. Ved å vurdere begge samtidig får virksomheten et solid grunnlag for å avgjøre hva slags data som kan brukes, under hvilke betingelser, og hvilke sikkerhetstiltak som må være på plass.
Nedenfor vises et eksempel på en klassifiseringsmodell som kombinerer datatyper og risiko, og som kan brukes som beslutningsstøtte ved vurdering av KI-bruk i virksomheten
Tabell 3 Klassifisering av data for bruk i språkmodeller
|
Dataklasse |
Mulige konsekvenser/risiko ved feil bruk eller utilsiktet deling |
Eksempel på data |
Anbefalinger for bruk |
KI-assistent nivå |
|---|---|---|---|---|
|
A – Åpne data |
Lav – ingen eller begrenset skade, f.eks. ved bruk av allerede offentlig tilgjengelig informasjon. |
Offentlige datasett/data med åpne lisenser/åpne nettsider. |
Kan brukes til trening, evaluering og i instrukser. |
1, 2, 3 |
|
B – Rettighetsbelagte data |
Middels – mindre skade, som brudd på interne retningslinjer, tap av tillit eller avtalebrudd/ økonomisk tap. |
Innhold som er beskyttet av opphavsrett, lisenser eller avtaler som artikler, kjøpt innhold, rapporter med IP-rettigheter. |
Kan ikke brukes til trening uten avtale. Bruk til instrukser krever vurdering av bruksrett. |
2, 3 |
|
C – Interne data |
Lav eller middels. |
Dokumenter og informasjon som ikke er offentlig, men heller ikke sensitive som interne rutiner, interne maler og rapporter. |
Kan brukes til interne evalueringer og instrukser. Bruk til trening bør vurderes nøye. |
2, 3 |
|
D – Personopplysninger eller andre konfidensielle data |
Høy – alvorlige brudd, som personvernkrenkelser, økonomisk tap eller uopprettelig tap av omdømme/tillit. |
Opplysninger om personer, kunder eller ansatte som er underlagt personvern eller taushetsplikt som kundedata, HR-info, sensitive vurderinger. |
Bruk til trening bør vurderes nøye. Instruering kun i kontrollerte, interne modeller. Kan kreve risikovurdering (DPIA/FRIA, se kapittel 4) |
3 |
|
E – Strengt konfidensielle eller / sikkerhetsgraderte data |
Kritisk – svært alvorlige forhold, som trusler mot liv, sikkerhet, nasjonale interesser eller samfunnsfunksjoner. |
Informasjon som kan skade virksomheten eller samfunnet dersom den kommer på avveie, som strategiske dokumenter, sikkerhetsgraderte data. |
Skal ikke behandles av språkmodeller uten særskilt tillatelse og høy sikring. Kan kreve risikovurdering (DPIA/FRIA, se kapittel 4) |
3 |
2.7 Oppsummering – Nøkkelspørsmål for definisjon av behov og avgrensninger ved bruk av KI-assistenter
For å vurdere om du har definert behov og avgrensinger godt nok kan du bruke disse nøkkelspørsmålene som et utgangspunkt:
Tabell 4 Nøkkelspørsmål for å definere behov og avgrensninger for bruk av KI-assistenter
|
Spørsmål |
Hva må avklares |
|---|---|
|
Hvilket problem vil vi løse – og/eller hvilken ny verdi vil vi skape og hvordan skal verdiene realiseres? |
Formuler enten et tydelig forbedringsområde (f.eks. «30 % raskere saksbehandling») eller en ny mulighet (f.eks. «personalisert opplæring vi tidligere ikke kunne tilby»). Måter å realisere på kan f.eks. være gjennom redusert ressursforbruk, kortere svartider, kvalitetsforbedringer og økt inntjening. |
|
Hvor mye tid og ressurser skal vi bruke på innføring av KI-assistenter |
Sett opp et budsjett både for intern tidsbruk, lisenser, og utviklingskostnader. Eksempler: Én dedikert produkteier (40 %), maks tre superbrukere (20 % hver); månedlig modell-kost ≤ NOK 30 000 i pilot; konsulenthjelp begrenses til 200 t |
|
Hvem skal bruke løsningen – og i hvilke arbeidsprosesser? |
Identifiser brukere, konkrete scenarier og hvilken del av prosessen KI-assistenten/agenten skal forbedre eller muliggjøre Brukere av løsningene kan f.eks. være internt ansatte, kunder eller innbyggere. |
|
Hvilke data trenger assistenten tilgang til, og hvilken sikkerhets- eller lovklasse gjelder disse dataene? |
List opp kildedata, vurder kvalitet på data som skal inngå, GDPR-klasse og eventuelle behov for kobling til andre fagsystemer Skal KI-assistenten bruke åpne data eller beskyttede data? Se egen bolk som risikoklassifisering av data |
|
Hvilket språk er mest relevant for brukerne? |
Skal instrukser og svar kun være på ett bestemt språk, eller åpnes det for ulike språk Eksempel: Fokuser på norsk regelverk og norsk språk; avvent engelsk, polsk og spansk svarmodus til fase 2. |
|
Når er vi fornøyd med kvaliteten på svarene? |
Sikrer realistiske forventninger og riktige testprosedyrer. Eksempler: 90 % av svarene skal vurderes som nyttige av pilotbrukere; kritiske feil ≤ 1 % |
|
Skal brukeren alltid ha siste ord, eller kan assistenten utføre oppgaver autonomt (-> agentisk KI) |
Balansere risiko mot gevinst; unngå over-autonomi for tidlig. Eksempel: Assistenten foreslår utkast – menneske trykker «Send». Ingen selvkjørende handlinger i fase 1. |
|
Hvilken ny kompetanse trenger vi? |
Vurder om det trengs ny intern kompetanse, og hvor mye ressurser som må settes av til opplæring av brukere for å få full nytte av løsningen |
Når dere har gode svar på de spørsmålene som er relevante for dere, er tiden moden for å gjøre organisasjonen og de ansatte klare til å ta i bruk teknologien organisasjonen og de ansatte er klare til å ta i bruk teknologien.